Witaj w notatkach do lekcji numer 2 kursu FastAI dedykowanej pojęciu stochastic gradient descent. Jeżeli przerobiłeś ze mną lekcję pierwszą, to wiesz mniej więcej, jak możesz skonstruować własny klasyfikator obrazków. Jeśli dodatkowo odrobiłeś zadanie domowe, to potrafisz już zrobić taki klasyfikator na własne potrzeby. A jeśli jeszcze nie zrobiłeś, to nie musisz się martwić — zrobisz je na początku drugiej lekcji.
Zadanie domowe z lekcji 1
Okazuje się, że to, co zinterpretowałem jako wskazówkę (lesson2-download.ipynb) do zadania domowego, było jego rozwiązaniem. W praktyce i tak 90% czasu poświęciłem na zdobycie obrazków, więc za wiele na tym nie zyskałem. A że zadanie i tak było łatwe, to za wiele na tym nie straciłem. Tak sądzę. Jeśli masz podobnie, to absolutnie się nie spinaj. Co więcej, zgadzam się z Jeremy — nawet jeśli nie skumałeś lekcji pierwszej, to i tak powinieneś zabrać się za drugą i kolejne, może się bowiem okazać, że akurat jakiś brakujący trybik znajduje się właśnie tam. W ogóle koncepcja liniowego uczenia się to często słaby pomysł. Warto skakać do przodu, do tyłu, powtarzać materiały, podglądać przyszłe lekcje, kombinować i ogólnie poczuć się jak dziecko budujące z lego, plasteliny i chwastów jednocześnie.
Odnośnie do samego proponowanego rozwiązani to nie rozgryzłem jeszcze co zrobić, żeby widget do usuwania nieprawidłowych obrazków zadziałał w Google Colab, ale chyba dam sobie z tym spokój. Aczkolwiek wprowadzenie takiego poziomu interakcji do Notebooków Jupyter wygląda kosmicznie interesująco.
Matematyka
Deep learning, jak i całe uczenie maszynowe jest oparty o matematykę. Trzeba jej trochę liznąć, aby jednak wiedzieć, czym i jak będziemy się zajmować. Pierwszą taką koncepcją jest funkcja liniowa:

Nie będę się rozpisywał, czym jest funkcja liniowa — jeśli zaliczyłeś maturę, to wiesz, a jeśli nie, to tu się dowiesz ;-). Dla nas natomiast jest ważne, że możemy ją przepisać do takiej postaci:

W naszym problemie nie będziemy mieć jednego takiego równania, ale będzie ich wiele, musimy więc uczynić nasze równanie trochę bardziej ogólnym:

Koniec końcu nasze zagadnienie sprowadzi się do takiej postaci:
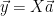
Czyli do przemnożenia macierzy przez wektor. Mnożenie to można sobie przypomnieć np. tutaj.
Jeżeli nasz problem możemy sprowadzić do macierzy, wektorów i operacji algebraicznych typu iloczyn skalarny to jest spoko. Na pierwszy rzut oka jest to strasznie skomplikowane i mozolne, szczególnie jeśli trzeba to liczyć ręcznie na egzaminie, ale komputery rozwiązują to w mgnieniu oka. Wydaje się to więc być dobrą ścieżką. Przynajmniej jeśli chodzi o trudność dla komputera.
Stochastic gradient descent
W ćwiczeniu, które rozwiązujemy w trakcie tej lekcji mamy dwie wartości a: a_1 = 3 i a_2 = 2. Symulujemy sobie przypadkowość, dodając do wyniku y jakieś losowe wartości. Nasz wykres nie będzie wiec całkiem liniowy:

Widzimy więc, że mamy tutaj jakiejś „rzeczywiste” zjawisko. Mamy jedną zmienną niezależną x i zmienną zależną y. Zapominamy w tym momencie o parametrach a_1 i a_2, bo będziemy chcieli je wyznaczyć. Jeżeli będziemy w stanie to zrobić dla jednej zmiennej niezależnej, to będziemy w stanie zrobić to dla dowolnej ich ilości. Oczywiście o ile będzie miało to sens.
Jak się za to zabrać? Ano będziemy testować różne zestawy a_1 i a_2 i sprawdzać, czy zaproponowana przez nie funkcja liniowa daje odpowiednio mały błąd (loss). A jak będziemy mierzyć ten błąd? W przykładzie mamy błąd średniokwadratowy mse.
Ok, ale będziemy wstawiać tam losowe wartości? Czyli będziemy atakować ten problem metodą brute force, aż nam się znudzi? Możemy sobie np. wstawić parametry -2.0 i 2.0 i zobaczyć jaki wynik otrzymamy:

Szału nie ma (mse = 8.0780), a możemy tak długo.
Mamy tutaj dwa parametry i każdy z nich może być niezależnie większy lub mniejszy. Daje nam to dość dużo kombinacji do sprawdzenia. Chcemy wyznaczyć minimum naszej funkcji błędu, tj. chcemy, aby mse było jak najmniejsze.
Zacznijmy od wybrania losowej wartości parametrów (np. wspomniane -2 i 2). Zastosujmy teraz pochodną funkcji straty do wyliczenia nowych lepszych parametrów i policzmy błąd (loss). Powtarzajmy to, aż będziemy zadowoleni. Musimy pamiętać jeszcze o learning rate — musi to być wartość na tyle mała, żebyśmy mieli szansę dotrzeć sensownie blisko minimum, a na tyle duża, żeby nie trwało to zbyt długo. Dzikie nie? Muszę przyznać, że akurat tyle zrozumiałem z video fastai.
Stochastic gradient descent — podejście numer 2?
Po obejrzeniu tego video trochę lepiej mi się to ułożyło w głowie. Chodzi tutaj o to, że wyliczamy pochodną z funkcji błędu z podstawionymi już tam wartościami x i y. Czyli, że do naszej funkcji wstawiamy x i y i wyliczamy pochodne cząstkowe. A wyliczanie pochodnych cząstkowych z takiej funkcji jest nazywane po prostu wyliczeniem gradientu. Gdy już wyliczymy te pochodne, to możemy sobie je zapamiętać i wykorzystywać dalej w obliczeniach. Teraz wstawiamy w nie nasze parametry i wyznaczamy ich wartość w tym punkcie. W ten sposób dostajemy informację, jak bardzo funkcja straty zmienia się w tym punkcie. A naszą funkcją jest wynik mse w tym punkcie.
Teraz gdy znamy tę zmianę, to możemy wyliczyć kolejną parę parametrów do sprawdzenia. Dla każdego parametru bierzemy jego pochodną cząstkową i mnożymy ją przez learning rate (np. 0.01). Bierzemy przetestowany parametr i odejmujemy od niego powyższy wynik. Wciąż brzmi to trochę dziko, ale pewnie z praktyką mocniej się wyklaruje.
Pozwolę sobie tutaj wypunktować podsumowanie algorytmu z powyższego video:
- Policz pochodne cząstkowe funkcji straty dla każdego parametru.
- Wybierz losowe wartości parametrów.
- Wstaw te parametry do pochodnych cząstkowych.
- Wyznacz wartości kroków.
- Wyznacz nowe parametry, biorąc stare parametry i odejmując od nich wartości kroków.
- Wróć do kroku 3, chyba że nowe parametry są zbyt podobne do starych (albo skończył się limit powtórzeń), wtedy przerwij.
Poznałeś właśnie fundament miliardowych biznesów — jak się z tym czujesz?
Cały ten proces to gradient descent. A gdzie część stochastic? Otóż jeżeli naszych zmiennych niezależnych (albo obserwacji) będzie za dużo, żeby zmieścić się w pamięci, trzeba będzie je podzielić na porcje. Dokonamy wtedy takiej samej operacji jak powyżej, ale na jakiejś porcji losowych obserwacji. Po przerobieniu takiej porcji zaktualizujemy parametry i jeżeli wyczerpiemy wszystkie obserwacje, to zakończymy jeden krok. Nic więcej tutaj się nie będzie dziać.
Trochę to pokręcone. Nawet dla mnie, mimo iż skończyłem swego czasu fizykę na PWr. Jednak z drugiej strony, nie jest to czarna magia — są to po prostu pochodne cząstkowe. Myślę, że problemem jest tutaj trzymanie odpowiedniej ilości abstrakcyjnych obiektów w głowie. Ja mam uczucie, że do pełnego wyczucia tego zagadnienia brakuje mi jednego slotu. Dobra wiadomość jest taka, że da się to wyćwiczyć. A może już masz jakiś fajny sposób na ogarnięcie tego tematu? Daj znać w komentarzu! Napisz również komentarz, jeśli zupełnie nie ogarniasz, o co tutaj chodzi. A nuż akurat mnie albo komuś innemu przyjdzie na myśl jakaś sensowna wskazówka? Albo przeformułowanie jakiegoś zdania?
Jeśli interesuje Cię jakiś temat – nie musi być związany z tym artykułem – to zostaw mi sygnał tutaj. Dzięki!
Artykuły z serii Deep Learning z FastAI: