Powróćmy na chwilę do uczenia nienadzorowanego. Dwa artykuły temu pisałem o jednym z prostszych i jednocześnie użytecznych algorytmów – k-średnich. Zapoznaliśmy się ze sposobem jego działania i z wynikami które dzięki niemu uzyskujemy (koncentrycznie pogrupowane obserwacje). Nie umknęła nam też największa wada tego algorytmu – ustalanie liczby grup, które chcemy uzyskać (tytułowe k). Czasem ustalenie tej liczby nie stanowi problemu (odgórna dobrze zdefiniowana potrzeba biznesowa), a czasem nie mamy pojęcia, ile to k powinno wynosić. W niniejszym artykule chciałbym pokazać Ci, jak możemy ugryźć i ten problem. Do jego rozwiązania użyjemy wartości zwanej Silhouette Coefficient. Przejdźmy więc do konkretów
Dobra grupa
W czasie naszych rozważań nie zastanowiliśmy się jeszcze nad tym, czym jest dobra grupa. Co mamy na myśli poprzez stwierdzenie, że dobrze pogrupowaliśmy nasze obserwacje? Każdy zbiór obserwacji możemy podzielić na co najmniej dwie grupy. Możemy też zwiększać ilość grup, aż dojdziemy do ilości grup równej ilości elementów – uzyskamy w ten sposób grupy jednoelementowe. Algorytm k-średnich będzie nam tutaj tworzył takie podziały, jakie mu zlecimy, bez żadnych uwag. Stworzymy w ten sposób różne grupy i fajnie byłoby określić, która sytuacja jest dla nas bardziej sensowna.
Przyjęło się w analizie danych, że w miarę sensowna grupa to taka grupa, która ma odpowiednio gęsto rozmieszczone obserwacje i jest dość dobrze odseparowana od innych grup. Jak są zdefiniowane te „odpowiednio” i „dość dobrze”? Nie są. Zawsze jest to sytuacja względna, zależna od kontekstu dostarczonego przez dane. Przyjrzyjmy się, co na ten temat ma do powiedzenia algorytm Silhouette.
Silhouette
Silhouette to nic innego jak … sylwetka. Proste, nie? Szczególnie w naszym przypadku. Prawda jest jednak taka, że nie mam pomysłu, dlaczego ten algorytm tak się nazywa. Mogę sobie zgadywać, że chodzi o ocenę sylwetki grupy, którą utworzyliśmy, ale to tylko zgadywanki.
Algorytm silhouette polega na wyliczaniu średnich odległości wewnątrz grup i ich najbliższych sąsiadów. Algorytm to może za dużo powiedziane, bo sprowadza się on do wyznaczenia współczynnika silhouette. A jak wygląda taki współczynnik? Jest raczej prosty:
$$s = \frac{b – a}{max(a, b)}$$
rozgryźmy więc elementy tego równania:
- a – średnia odległość danej obserwacji od wszystkich innych obserwacji w grupie
- b – średnia odległość danej obserwacji od wszystkich innych obserwacji w innej najbliższej grupie
– większa wartość z wartości a i b.
Po pierwsze, widzimy tutaj, że chodzi o współczynnik silhouette dla pojedynczej obserwacji. Żeby wyznaczyć współczynnik silhouette dla całego naszego podziału na grupy, wystarczy wziąć średnią współczynników indywidualnych.
Po drugie, musimy zastanowić się, jak interpretować sytuację z funkcją max(). Co się stanie, jeśli a będzie większe od b. Oznacza to, że ta jedna konkretna obserwacja ma dalej do obserwacji w swojej grupie (duża średnia odległość), a bliżej do obserwacji w grupie sąsiedniej. Równanie będzie wtedy wyglądać tak: 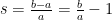

Pora na zastanowienie się, jakie cechy grup wyłapuje nasz współczynnik s. Z jednej strony, mamy wartość a, która mówi o bliskości innych elementów wewnątrz grupy. Nie jest to, może gęstość, ale zasadniczo mówi nam, czy nasza grupa jest dość ciasno upakowana. Mamy też wartość b, która pokazuje nam, jak daleko jesteśmy od najbliższej innej grupy. Czyli mówi nam o separacji. Im większa, tym lepiej się separujemy. Chcemy więc aby a było małe (blisko do „sojuszników”), i b duże (daleko do „wrogów”). Jeśli wrócimy do równania s, to okaże się, że im bardziej a jest mniejsze od b, to bardziej zbliżamy się do +1. A jeśli jest odwrotnie, to zbliżamy się do -1. Czegóż chcieć więcej?
Czy zobaczymy kiedyś wartości mniejsze niż 0?
Algorytm k-średnich jest fundamentalnie całkiem nieźle wykombinowany. Możemy więc zastanowić się, czy zobaczymy po jego użyciu współczynnik silhouette z wartościami ujemnymi? Skoro k-średnich tworzy grupy wokół dość mocno skoncentrowanych obserwacji, śmiem wątpić. Zawsze grupy będą od siebie odseparowane ze względu na dystans, a silhouette bazuje właśnie na dystansie.
Po co może nam więc być wyznaczanie współczynnika silhouette? Jedną odpowiedź już podałem – jeśli nie wiemy, ile grup chcemy mieć – wyznaczenie maksymalnej wartości silhouette może nam dać całkiem niezłe rozwiązanie problemu separacja-koncentracja i w ten sposób wyznaczyć nam najlepsze k. Druga odpowiedź to debugowanie. Czasem zdarzy nam się użyć funkcji grupującej, której do końca nie rozumiemy i chcielibyśmy sprawdzić, czy dobrze jej użyliśmy. Albo piszemy własną funkcję i chcemy ją przetestować. W dwóch wymiarach zrobimy sobie wizualizację i na oko ocenimy czy ma to sens. Jeśli natomiast mamy więcej wymiarów, współczynnik ten możne nam pomóc określić czy nie mamy gdzieś błędu (jeśli wypadną wartości ujemne).
A trzecia odpowiedź to odwieczna potrzeba porównywania. Jeśli pasuje nam sposób wyliczenia współczynnika s i uznamy, że jest to wyznacznik naszego sukcesu, to możemy go sobie wyliczyć dla wyników wielu algorytmów i hiperparametrów. Będziemy mogli je porównywać, aż nam się znudzi.
Przykład
Jako przykładu użyjemy skryptu z artykułu k-średnich, który odpowiednio rozszerzę. Użyłem wtedy danych ze znaczków turystycznych (długość i szerokość geograficzna) i zdecydowałem arbitralne, że podzielę je na 12 grup. Wyznaczmy więc współczynnik s dla takiego podziału:
# kod 1 from sklearn.metrics import silhouette_score silhouette_score(X = coordinates, labels = znaczki["grupa"])
Jak widzimy, do uruchomienia tej funkcji potrzebujemy dwóch parametrów: X i labels. X mówi nam o cechach, na których bazie uruchomiliśmy funkcję KMeans. labels to z kolei uzyskane numerki grup. Jeśli nie zmienialiśmy nic w funkcji KMeans, to nie będziemy też musieli nic więcej tutaj zmieniać. Warto jednak pamiętać, że jeśli zmienialiśmy metryki (z Euklidesa na inną), to w obydwu miejscach powinny być takie same.
Uzyskany współczynnik to s = 0.450639136417191. Jeśli spojrzymy na zakres -1 do +1 to całkiem nieźle. Ale tak jak wspomniałem, ujemnych wartości raczej nie zobaczymy, można by się więc zastanowić, czy nie da się lepiej.
Jak wyznaczyć więc najlepszą ilość grup? W pętli ;-P:
# kod 2
silhouette_averages = []
for ilosc_grup in range(2,len(znaczki)):
n_clusters = ilosc_grup
kmeans = KMeans(n_clusters = n_clusters,
random_state = 42)
kmeans.fit(coordinates)
znaczki["grupa"] = kmeans.labels_
sil_sco = silhouette_score(X = coordinates,
labels = znaczki["grupa"])
silhouette_averages.append(sil_sco)
if ilosc_grup % 10 == 0:
print(ilosc_grup,sil_sco)
W praktyce mamy tutaj to samo co wcześniej tylko dodatkowo zapisuję uzyskane s do listy i wypisuję s na ekran, gdy k jest podzielne przez 10. Ot, cała filozofia.
Zobaczmy, jak wygląda wykres s od ilości grup:

Ciekawa sprawa – zaczynamy dość wysoko, później stromy spadek i systematyczne podnoszenie się do góry. Aż do maksimum, powyżej którego mamy tylko spadek. Wychodzi więc, że możemy podzielić Polskę na dwa-trzy obszary „turystyczne”, natomiast nie powinniśmy jej dzielić na 18 (coś koło tego?) obszarów – bo nie będą ani się wyróżniać, ani nie będą wystarczająco upakowane pod względem atrakcji. Maksimum tej funkcji pojawia się dla 266 grup (tyle mamy ciekawych miejsc w Polsce?) gdzie s = 0.6116557772535383. Po tym maksimum nic już nie ugramy raczej sensowego, oprócz dotarcia do s = 0. Oczywiście pomijam tutaj kwestie wyboru miejsca znaczka turystycznego (zakładam, że wszystkie ciekawe miejsca dostały znaczek) i kwestie nieliniowości szerokości geograficznej (kiedyś opiszę odpowiednią konwersję, funkcje KMeans i Silhouette będą działać tak samo). Widzimy więc, że taką prostą pętlą i współczynnikiem Silhouette możemy spróbować wyznaczyć wartość k. Pozostanie nam jeszcze pytanie o sensowność tej wartości.
Podsumowanie
Jeśli chcemy pogrupować różne obserwacje, sięgamy po uczenie nienadzorowane. Nazywa się ono nienadzorowane, bo nie da się nadzorować modelu, który budujemy. Możemy jednak spróbować tego dokonać nie na wprost, analizując na różne sposoby uzyskane wyniki. Jednym z takich sposobów jest wyliczenie współczynnika silhouette, który mówi nam, czy uzyskane wyniki są wystarczająco upakowane i odseparowane. Wciąż nie wiemy, jak daleko jesteśmy od rozwiązania idealnego (brak możliwości użycia zbioru testowego), ale możemy porównywać między sobą uzyskane rozwiązania.
Pełny kod użyty w artykule znajduje się tutaj.